# Regular expressions
Preface
In our case, regular expressions are a powerful tool for searching for any strings in user messages. They can be used as conditions for the subsequent execution of any actions in the "Regular Expressions" filter and in trigger conditions.
Agree, it is not always possible to explicitly (for example, using the "Message contains" condition in the trigger) specify what the bot should respond to. Without this tool, you can not say that the specified words should stand no further from each other than N characters from each other, it is not always convenient to list all the forms of the required word.
In addition, you can use regular expressions to make almost all the conditions (related to the message text) in triggers. Based only on this, we can understand that this tool will be able to open up wide opportunities for you.
Regular expressions are used in all popular programming languages, but each of them has small differences in syntax. To avoid misunderstandings, we warn you: ChatKeeperBot uses Java language regulars.
You can check your regular expression in your personal account, there is a "Help" button in the upper panel by clicking on "Test a regular expression".
How does it all work?
Despite the fact that it's all complicated, it's simple. After reading this article, you will be able to quickly understand the basic principles of the regulators, studying the examples we have given will become even more clear, but if you still have questions, we will answer them. So, let's start.
If you enter the regular expression (hello) in the regular expression tester, and the text below, then we will get an analog of the condition "The message contains":
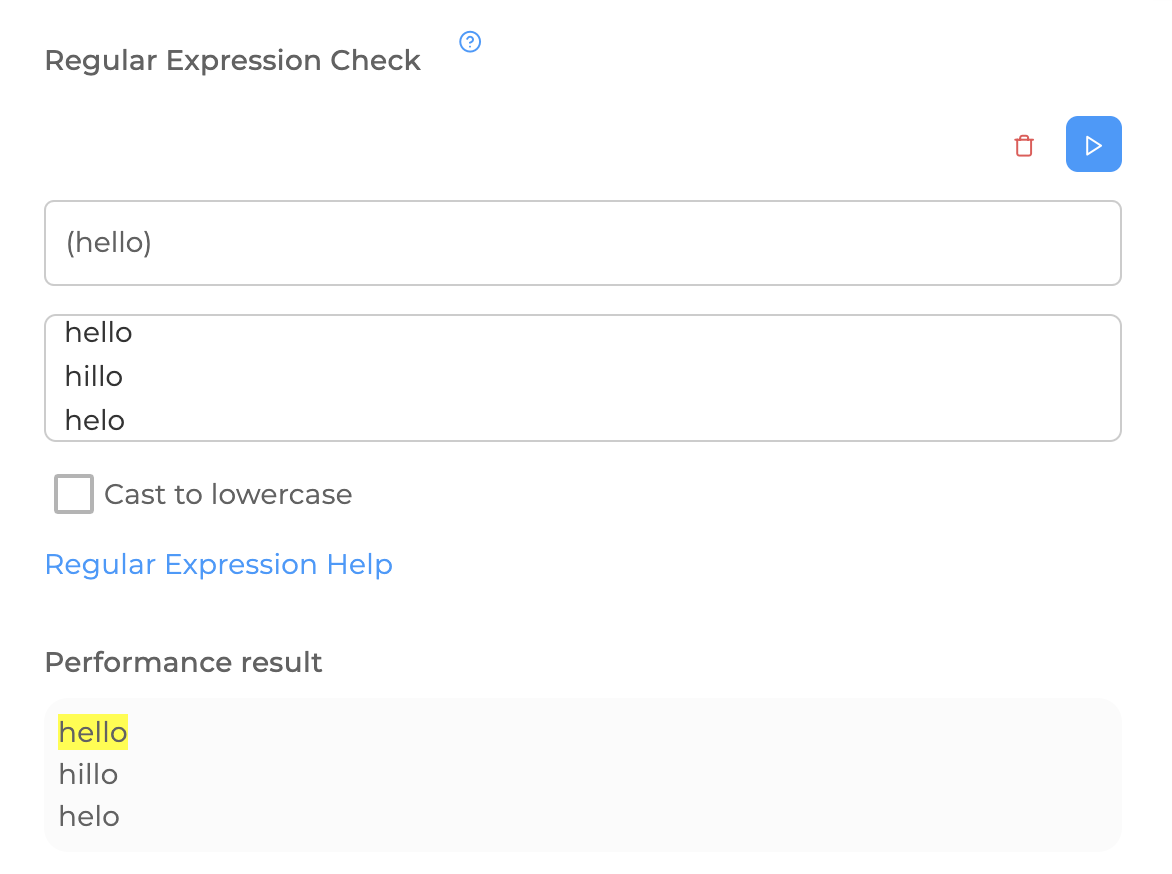
So, here we can trace the essence of regular expressions – they are designed to look for some pattern in the text, and in the case of @ChatKeeperBot – the word/expression in user messages that the trigger should trigger.
You can see that the regular expression is written in parentheses. They serve to highlight some common part, as in mathematics. In simple cases, like this one, they can be omitted. Over time, you will set them intuitively. I hope you have understood how to use the controller tester on our site – you need to enter a regular expression in the top line, and write a text below in which it will have to find (or not find) the template you need.
The text in the regular expression is case-sensitive. That is, if you write a regular (Hello), only the string "Hello" will correspond to it, but not "Hello". In order to ignore the case, you can check the box "Ignore the case"below in the filters of the condition
The symbols through which all the magic described above will occur are in this list:
. ^ $ * - + ? { } [ ] \ | ( )
If you need to find a string containing one of these characters (for example, the string "all."), you need to escape this character – add a backslash before the character. The regular schedule will look like this: (all.)
It's either me, or this disgusting floral wallpaper
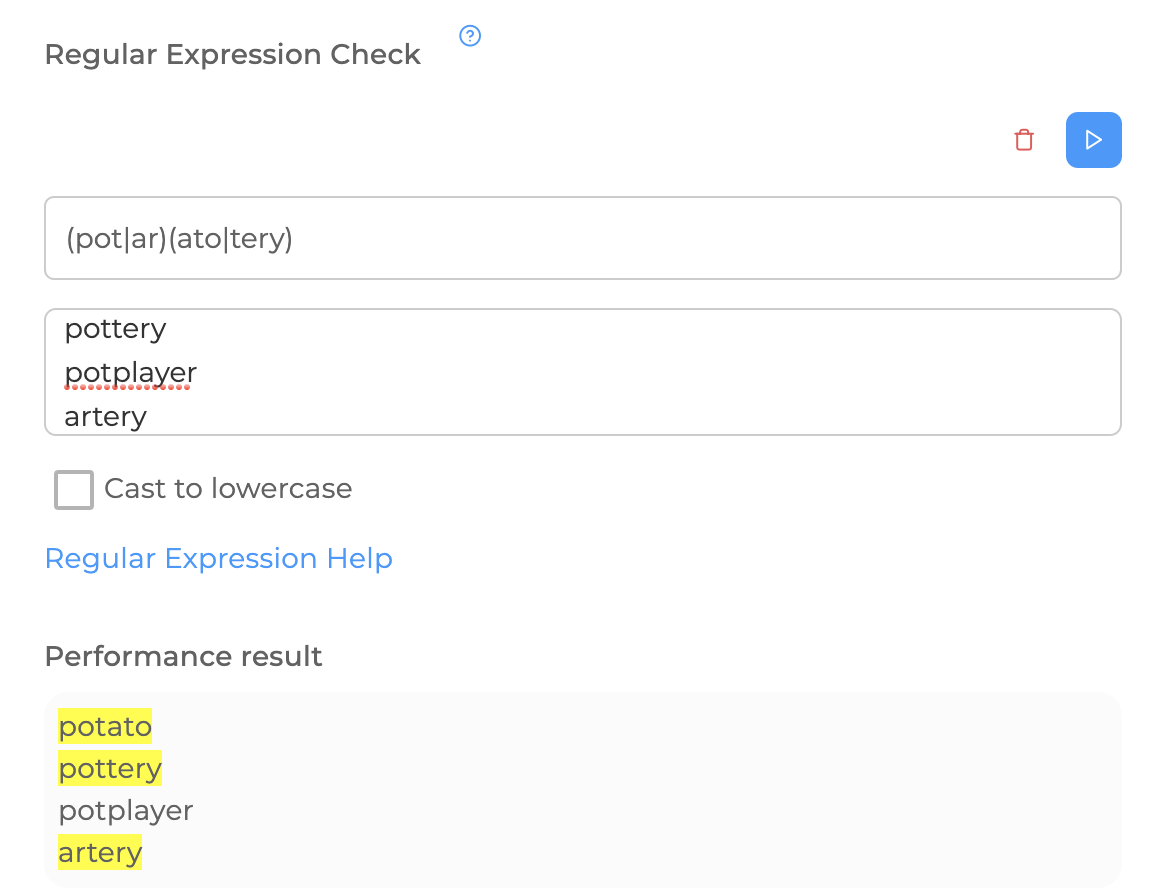
The very first thing I will introduce you to is the "| " sign. It is similar to the word "OR". Everything is very simple here: regular (re|dymo)(move|kur) will be triggered for 4 words: transition, smoke break, chimney, smoke hole.
** Sets**
To indicate that one of the listed symbols can stand in a certain place, sets are used. The necessary characters are written in square brackets.
If you put a " ^ " sign before the characters in the set, then the regular function will always be triggered when all the listed characters are not in this place.
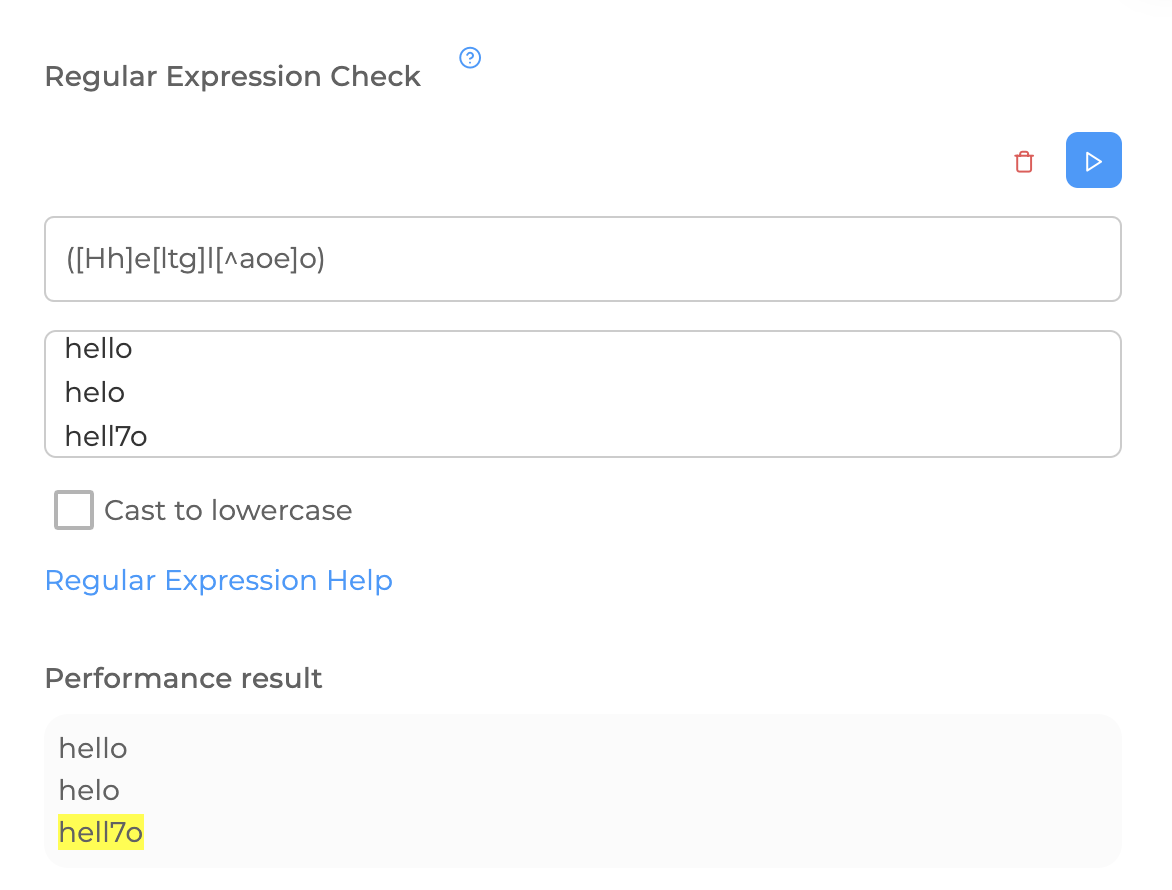
Explain to yourself why one example is accepted and the other is not suitable.
Also, the sets can be combined with each other:
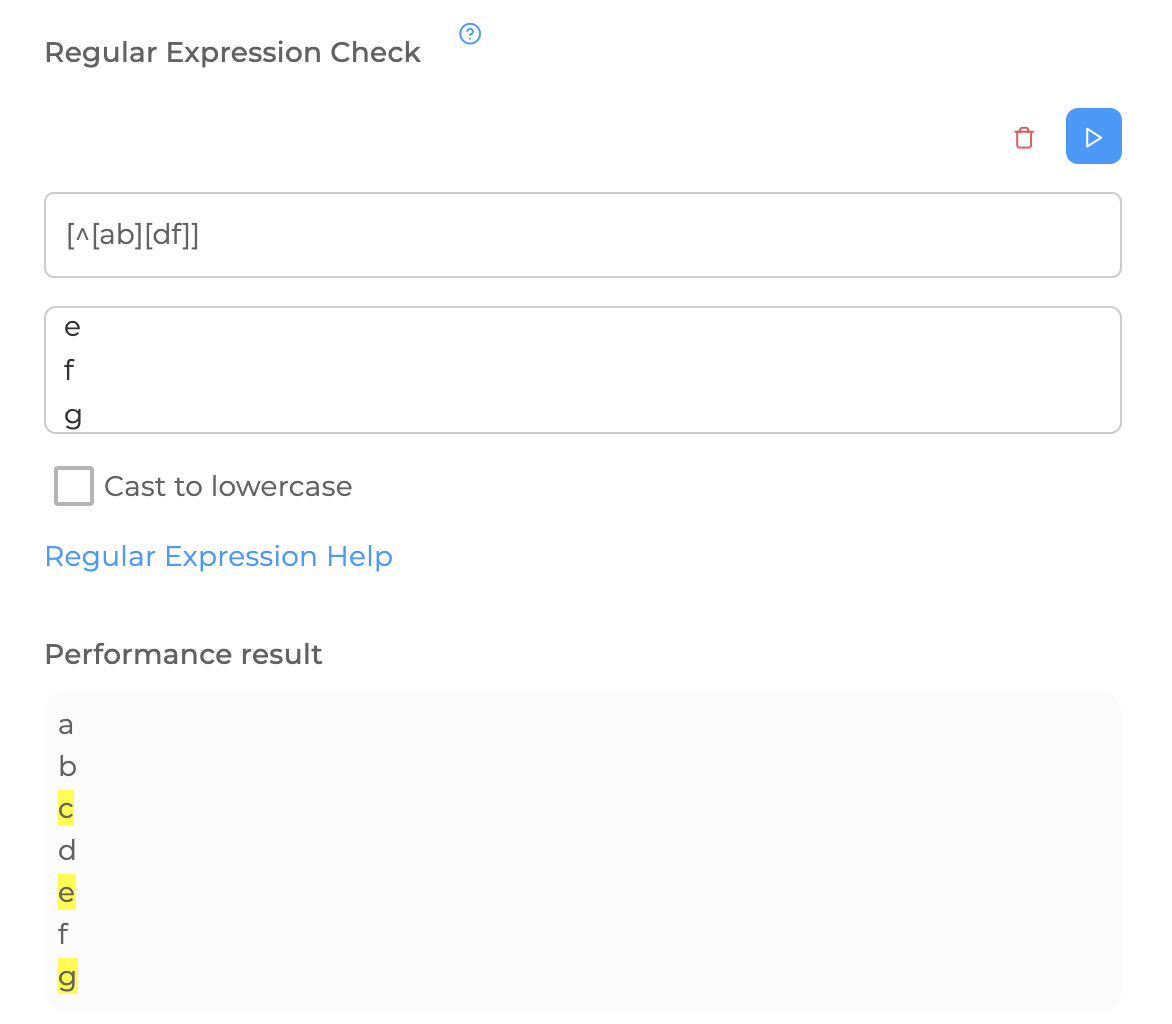
And a couple more tricks:
[a-g [f-z]] combining characters (from a to g and from f to z)
[a-z&&[klmn]] character intersection (characters k, l, m, n)
[a-z&&[^b-e]] subtracting characters (characters a, y, z)
Ranges
How would you designate any letter of the Russian alphabet? ([abvgdeezhzik.... – absolutely true, but it is very cumbersome. A dash can be used to indicate a range of characters: ([a-z]). This can be done due to the fact that in Unicode all the letters are arranged sequentially, except for the letter E. Thus, the letter of the Russian alphabet in lowercase can be written as follows: ([a-yae]), and without taking into account the case as follows: ([a-yaa-YaE]). By analogy, any digit: ([0-9]). The regular expression ([o-r]r[z-k][b-g]e[^a-su-i]) can correspond to the string "hello".
Once again, [fd7] is f OR d OR 7.
[^9qy] is NOT 9 AND NOT q is NOT s
For some sets that are used quite often, there are special designations. For example, \s is used to describe any invisible character (space, tab, line break), \d is used for digits, and \w is used for Latin characters, digits, and the underscore.
If these sets are written with a capital letter (\S, \D, \W), then they will change their meaning to the opposite: \S - any non-white character, \D - any character that is not a digit, \W any character except Latin letters, digits or underscores, respectively. If it is necessary to describe any character at all, a dot is used for this -".". Such sets are sometimes called metacharacters.
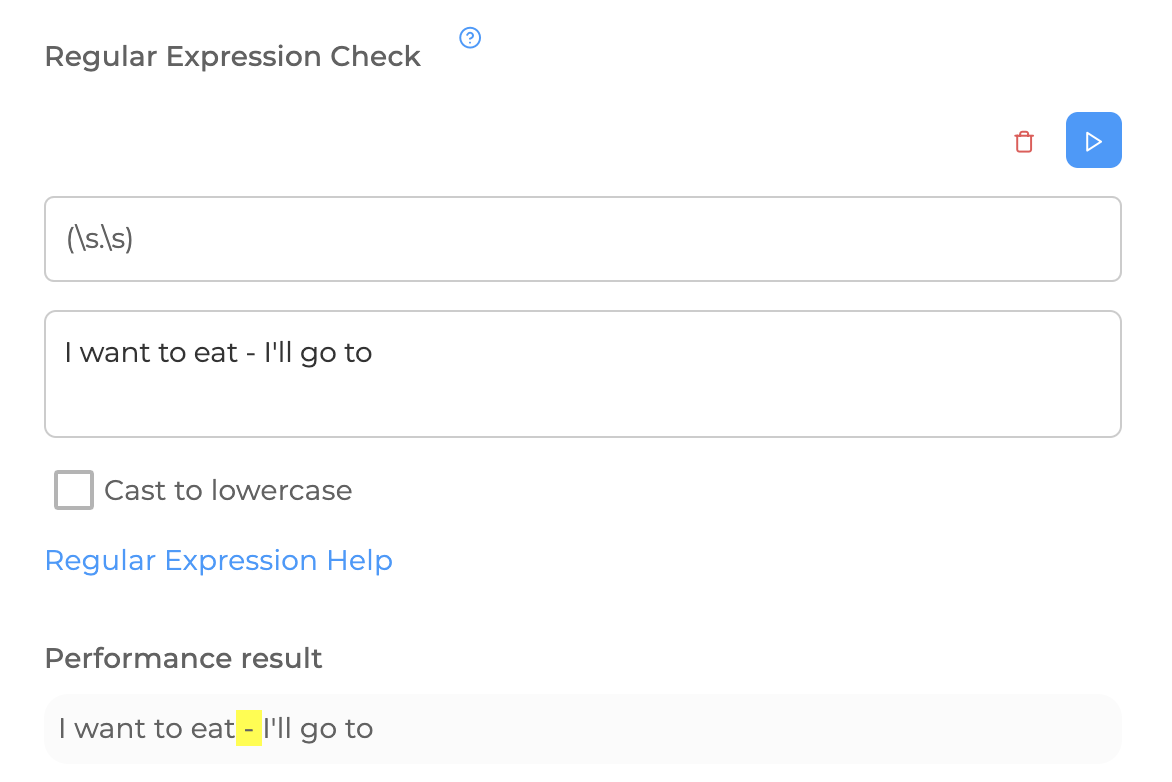
The search for characters limited to two "invisible" characters is implemented above. If there were three spaces in a row in the text, they would also be highlighted, since". " is absolutely any character, including a space.
Let's look at a couple of difficult examples:

The" non-digit " (\D) also includes line break characters, spaces, underscores, so the numbers "3" and "2" are highlighted in the first two lines, between which there is an invisible line break sign. The string "2q3" is not highlighted, because part of this string is already included in the previous template, and the search continued again with the characters "q3".
Another example:

Let's look at it in more detail. To the right and to the left \d – that is, numbers. What is in the middle? There is: not an invisible symbol and not a number. Based on this, the other templates can not be suitable.
Nothing is impossible. The boundaries are only in our heads.
The border or non-border of the word is indicated by the characters \b and \B. I offer an example for consideration:
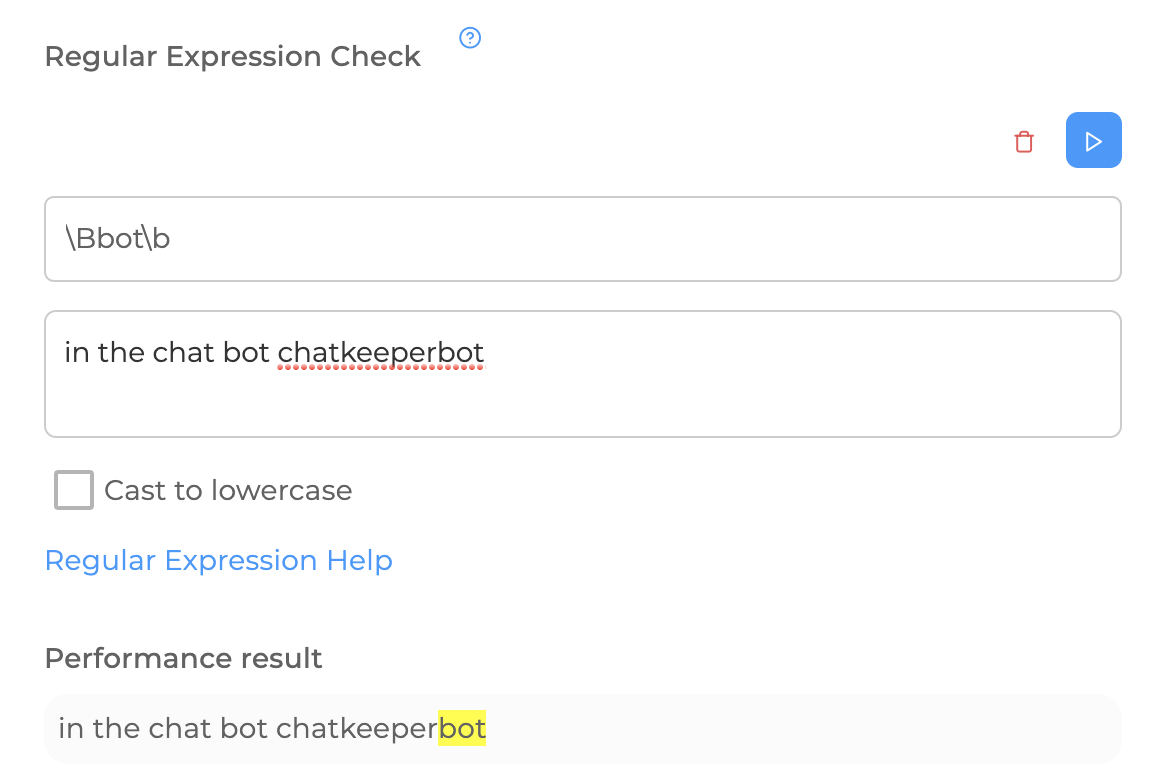
The ^ sign indicates the beginning of the input, $ - the end of the input.
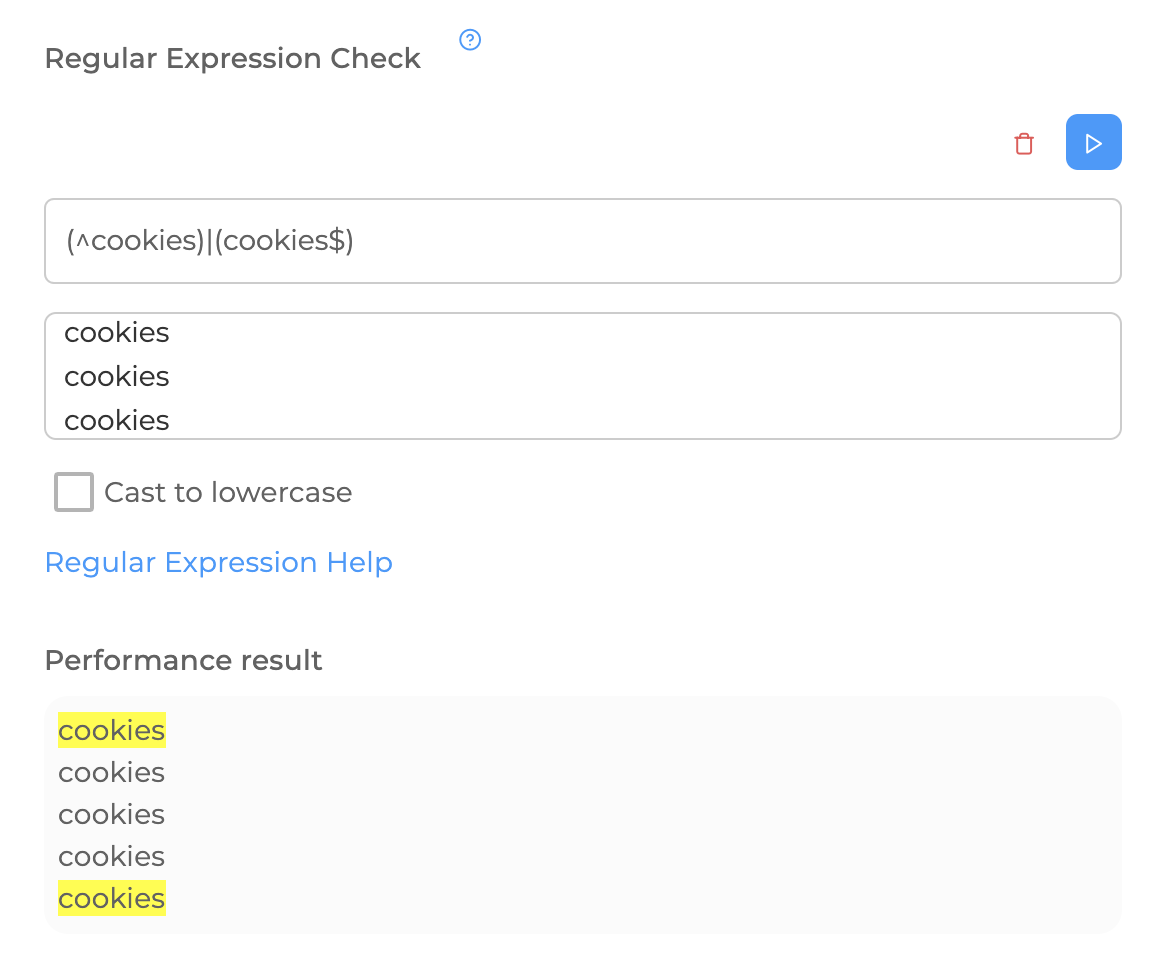
** Quantifiers (specifying the number of repetitions)**
This tool, for example, will allow you to find a difficult-to-guess phrase or expression in a user's message. Let's say you have a group related to cooking, and a lot of newcomers come there, asking how to make dishes, and you want to send them with such questions to some resource with this information. He can ask "how to make pizza", or "how to make this pizza", or "how do you make such pizzas", and instead of "this" and "such" there are fifty more options. Therefore, we must say that there are, say, 20 characters between the words "to do" and "pizza". You can do this as follows: the regular prive{1,5}t will correspond to the words "hello", in which from 1 to 5 letters" e "inclusive: "hello", "hello" or "hello". In addition, the second digit can be omitted: t {1,} t-means the letter "e" will occur one or more times in the word hello; e{3} – a certain number of times. In addition, there are special symbols for denoting some quantifiers, they are below. Let's summarize:
{n} the character is repeated n times
{n,} the character is repeated n or more times
{n,m} at least n times and no more than m times
? one or none (analog {0,1})
- zero or more times (analogous to {0,})
- one or more times (analogous to {1,})
So, let's go back to the example with pizza. Now we can do what we want, we will leave the letters "deeds" instead of the verb "to do", so that all forms of the word are captured (did, do, etc.), it's easier with pizza – you can leave only "pizzas":
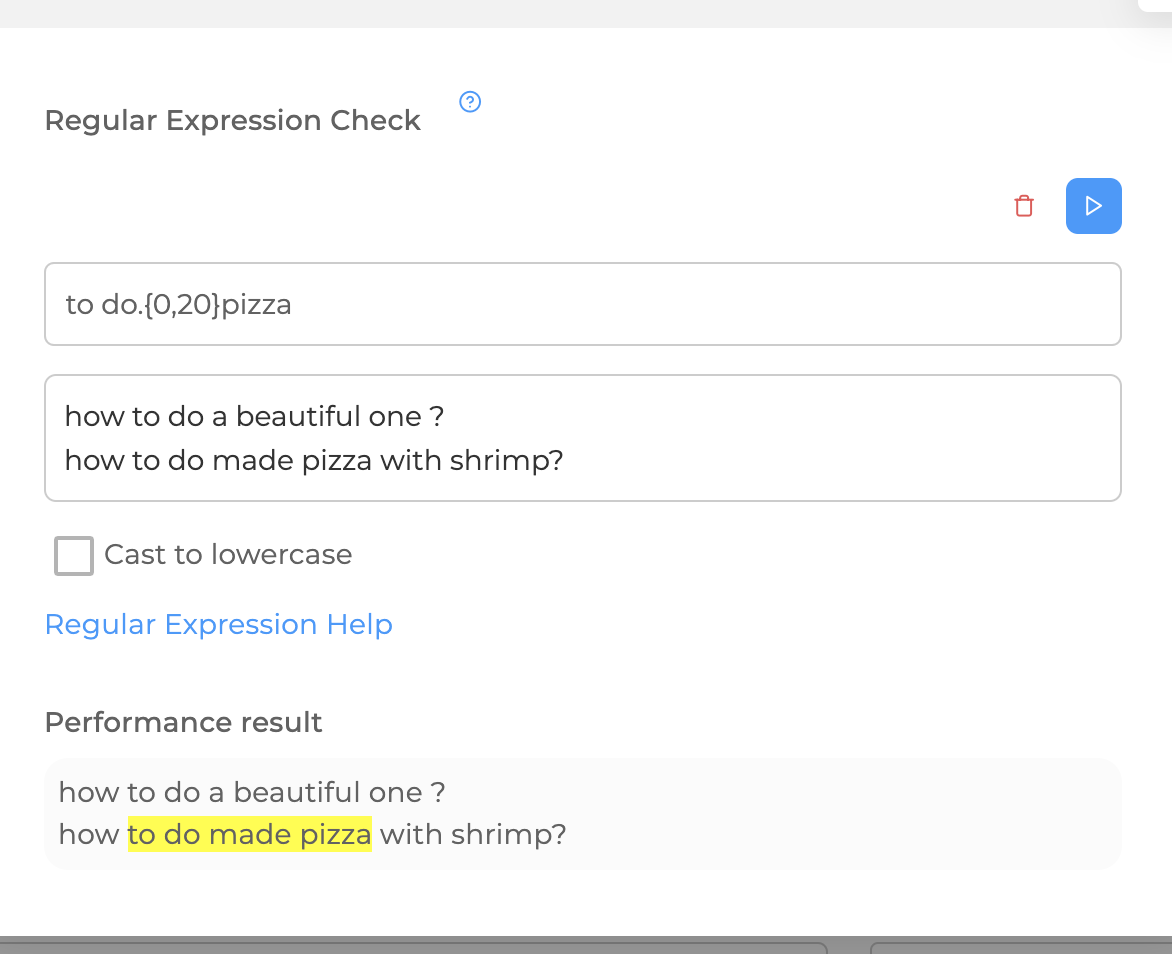
But there is a small mistake. There may be a message: "Such are the things, the pizza turned out to be tasteless", which will also work on a regular basis. What to do? It's very simple, specify the possible letters after the "things" for the verb
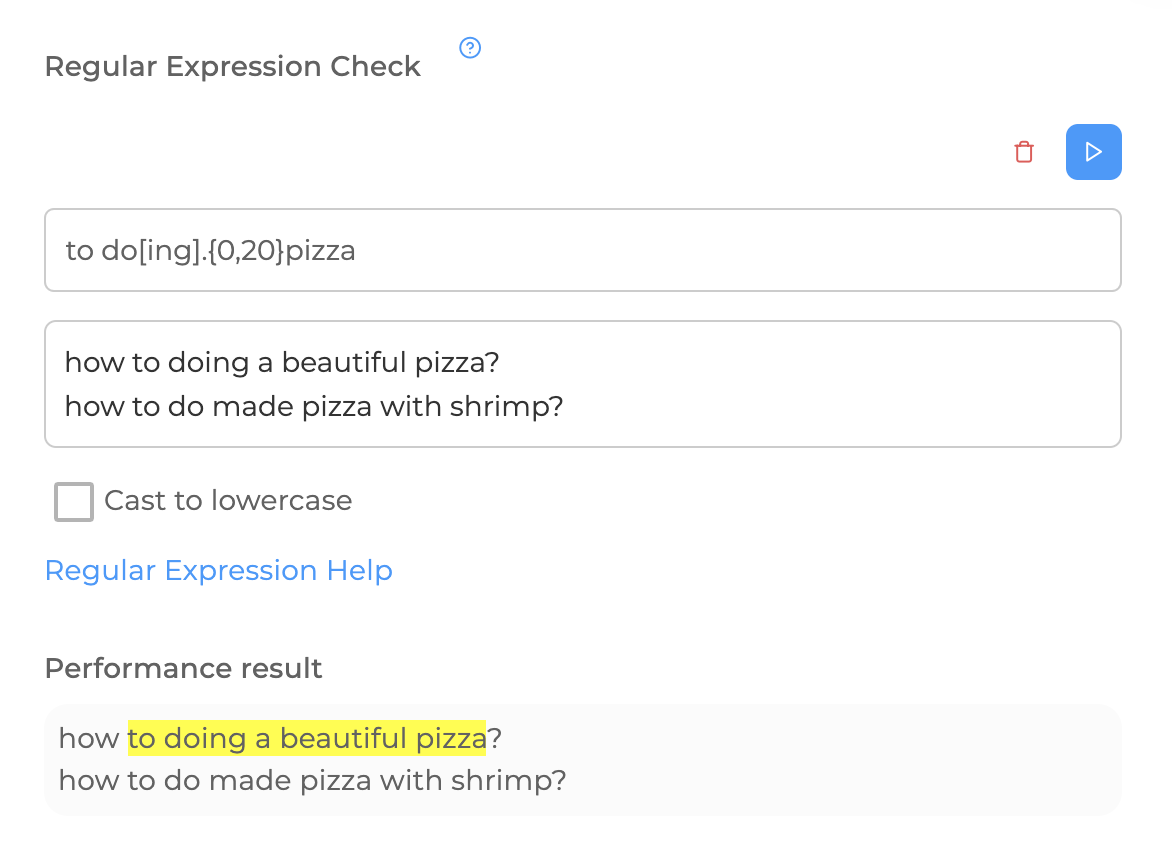
You can also add a question mark at the end, excluding the cases of statements, for example: "I know how to make such a pizza.". To do this, you can make a regular schedule like this: business[I'm flying].{0,20}pizzas.? At the end of the regular schedule, we say that after" pizzas "and before"? " there should be zero or more characters.
If you do exactly the right thing, you can simultaneously avoid the fact that these words will be in different predozheniye. Sentences can end with a period, an exclamation mark, or a question mark. And then we will replace the dots in the regular (any character) with "not the end of the sentence", necessarily escaping ". " and "?": [^.?!], for the second point, we will omit the question mark, since we need it. It will turn out: business[I'm flying][^.?!]{0,20}pizzas [^.!]?
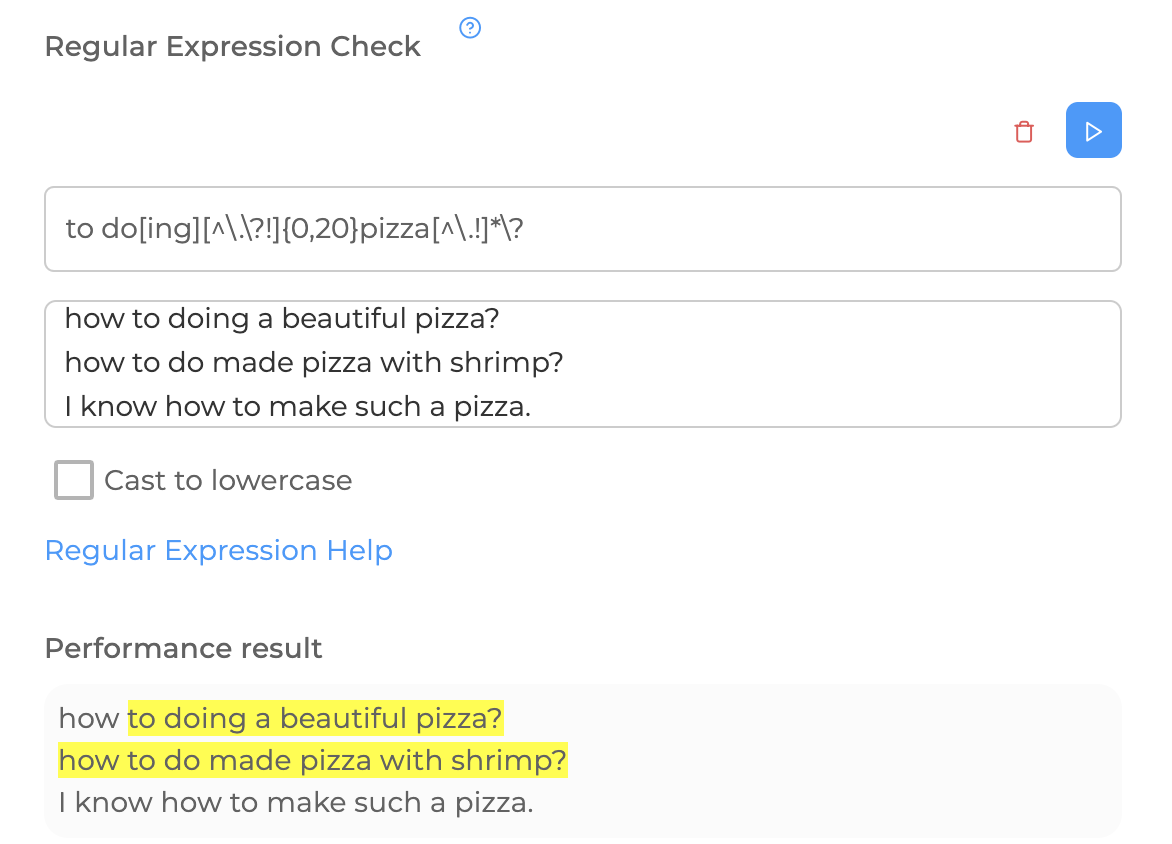

A table of popular metacharacters (not all of them are collected here, because firstly, the probability of using some is zero, and secondly, some are simply impossible to use in the bot).
^ the beginning of the line (the beginning of the message)
$ end of line (end of message)
\b word boundary
\B not word boundary
\d digital character
\D non-digital character
\s space character
\S non-whitespace character
\w alphanumeric character or underscore < br/>
\W any character other than an alphanumeric, numeric, or underscore < br/>
. any character
\t tab character
\n newline character
{n} the character is repeated n times
{n,} the character is repeated n or more times
{n,m} at least n times and no more than m times
? one or none (analog {0,1})
- zero or more times (analogous to {0,})
- one or more times (analogous to {1,})
/ logical "OR"
[a-z&&[klmn]] character intersection (characters k, l, m, n)
# Regular Expression templates
You can use ready-made regular expression templates for triggers and spam filters.
# Search for a phone number
Regular expressions for searching for different phone numbers can be useful for a group in several cases:
- protect the group from spam and fraud
- specify the mandatory conditions for publication. For example: a job advertisement indicating the phone number for communication.
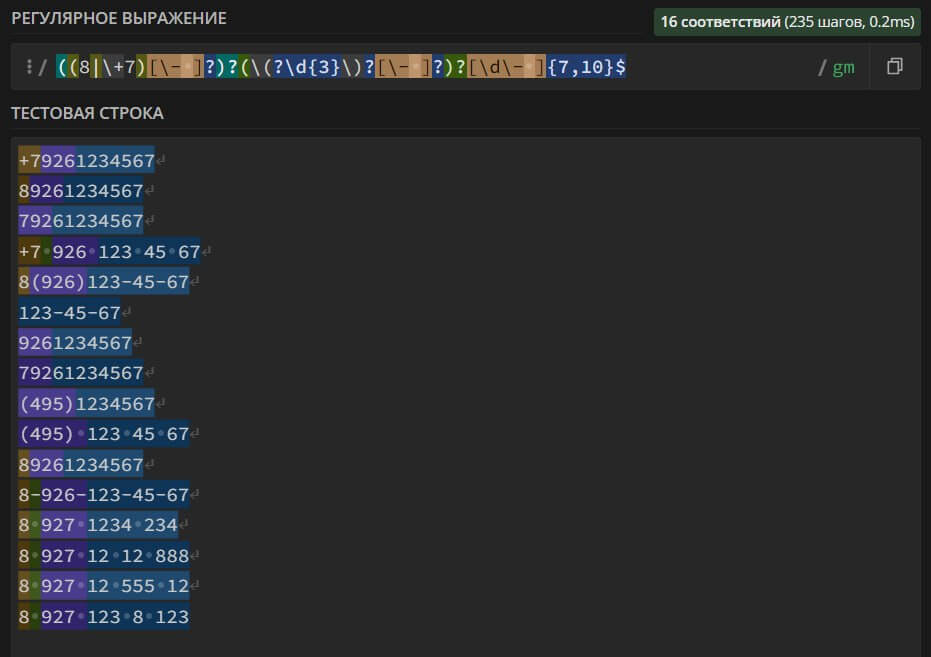
((8|\+7)[\- ]?)?(\(?\d{3}\)?[\- ]?)?[\d- ]{7,10}
– search for a landline or mobile phone number in the text, which may contain brackets " ()", dashes "-", spaces, the area code "8" or "+7" and consist of 7 to 10 digits, excluding the area code.
This regular expression is universal and suitable for searching all popular formats for writing mobile and landline numbers. It is equally suitable for combating spam and for checking group ads with mandatory indication of contacts.
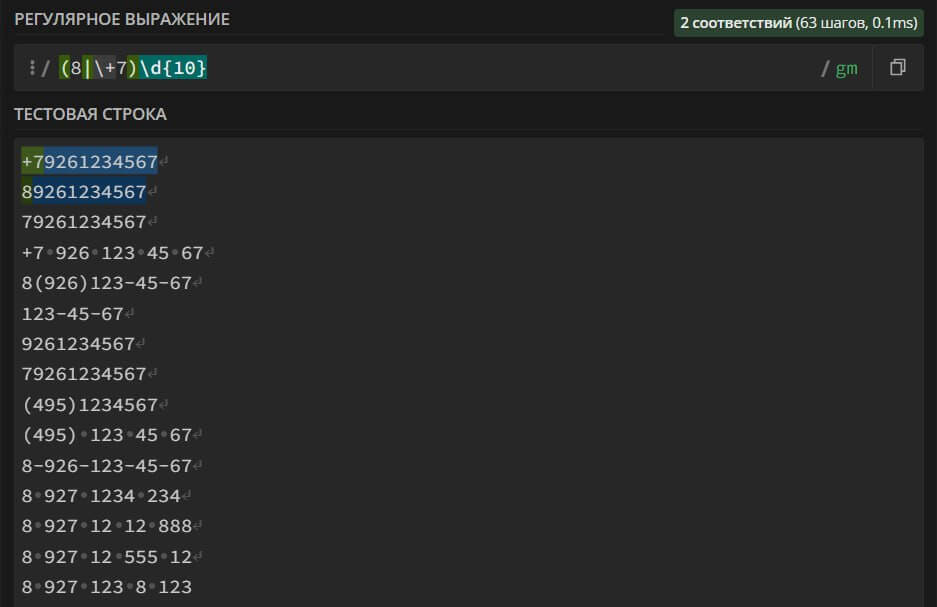
(8|\+7)\d{10} – search in the text for a mobile phone number that may contain the area code "8" or "+7". The number can consist of only 10 digits, excluding the area code.
This regular expression is strict. It is suitable for searching for only 2 formats of a mobile phone number. It is not suitable for anti-spam, but it can be used if you have strict requirements for publications in the group.
(8|\+7)(\-|()?\d{3}(\-|\))?\d{3}\-?\d{2}\-?\d{2} – search in the text for a mobile phone number that may contain brackets " ()", dashes "-", area code "8" or "+7". The number can consist of only 10 digits, excluding the area code.
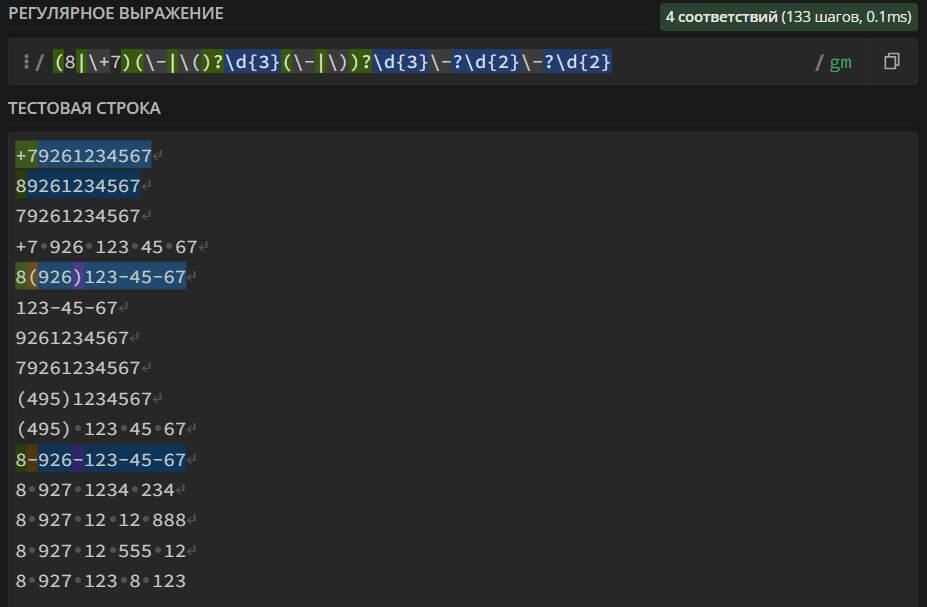
# Search for bank card numbers
Regular expressions for searching for different bank card numbers belong to the same categories: spam prevention and checking group ads.
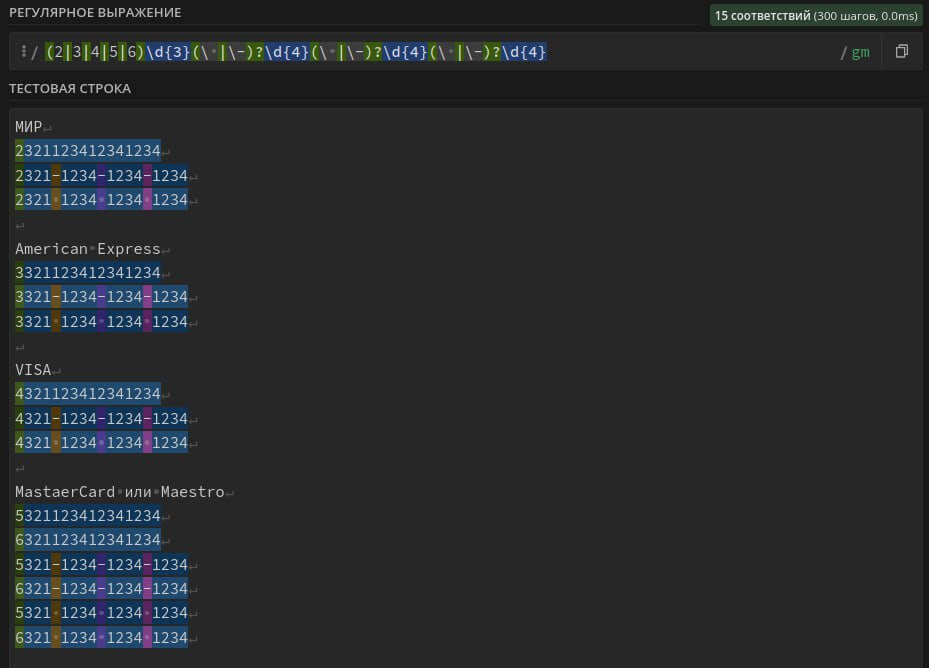
(2|3|4|5|6)\d{3}(\ |-)?\d{4}(\ |-)?\d{4}(\ |-)?\d{4} – search in the text for bank card numbers with the types of payment systems Visa, MasterCard, Maestro, American Express, MIR. The card number can contain spaces, dashes "-" and consist of 16 digits.
The regular expression is universal, suitable for searching all popular formats for writing bank card numbers and takes into account most payment systems.
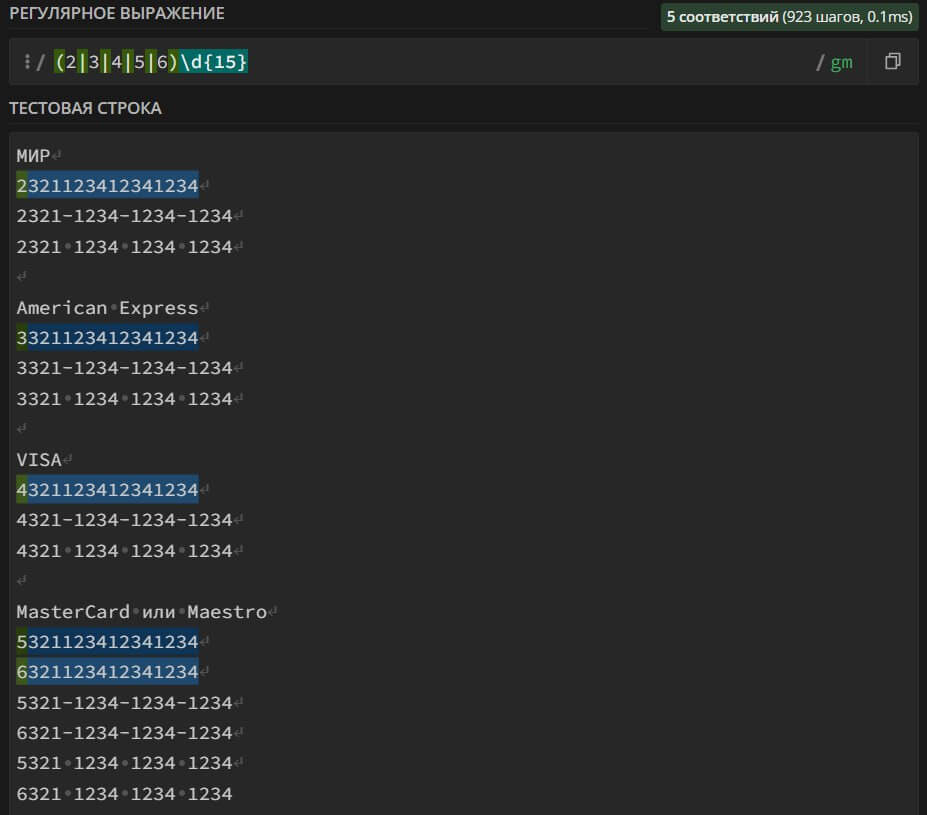
(2|3|4|5|6)\d{15} – search in the text for bank card numbers with the types of payment systems Visa, MasterCard, Maestro, American Express, MIR. The card number can consist of 16 digits.
A strict regular expression and with a limited type of number spelling check. Spaces and dashes are not taken into account. It reacts only to the combined spelling of the card number.
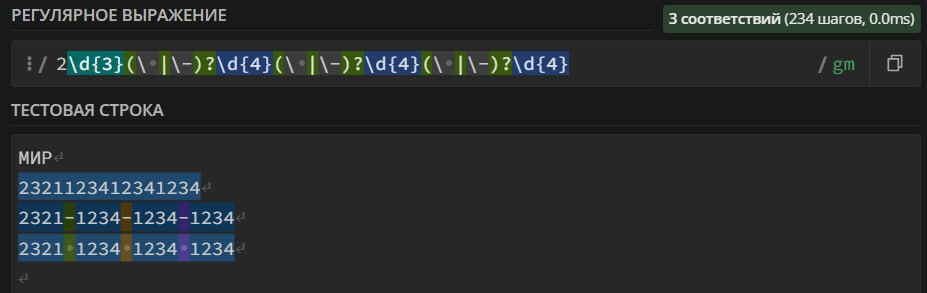
2\d{3}(\ |\-)?\d{4}(\ |\-)?\d{4}(\ |\-)?\d{4} – search in the text for the bank card numbers of the MIR payment system. The card number can contain spaces, dashes "-" and consist of 16 digits.
A regular expression for searching for cards of only 1 type of payment system. It can be used for Russian-language chats.
3\d{3}(\ |\-)?\d{4}(\ |\-)?\d{4}(\ |\-)?\d{4} – search in the text for bank card numbers of the American Express payment system. The card number can contain spaces, dashes "-" and consist of 16 digits.
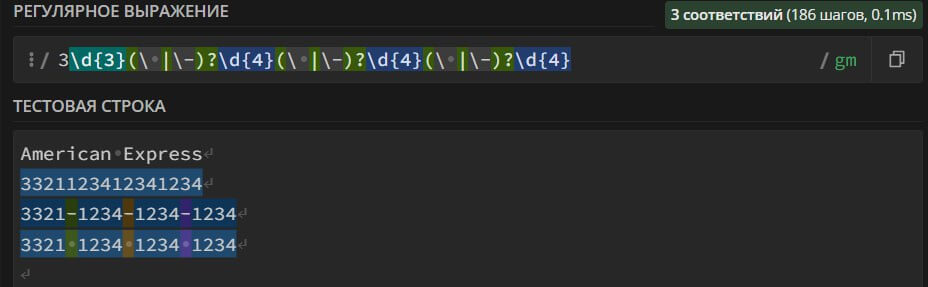
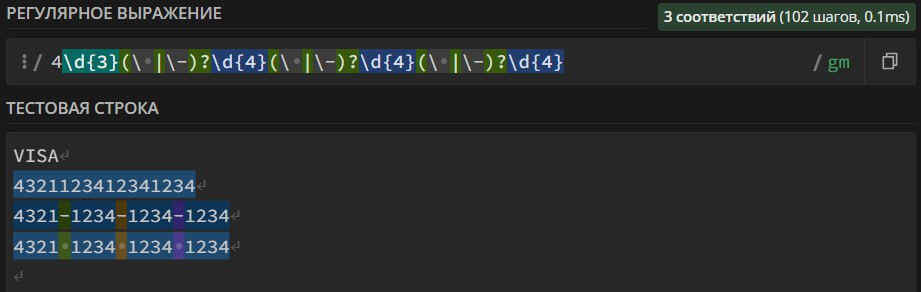
4\d{3}(\ |\-)?\d{4}(\ |\-)?\d{4}(\ |\-)?\d{4} – search in the text for bank card numbers of the VISA payment system. The card number can contain spaces, dashes "-" and consist of 16 digits.
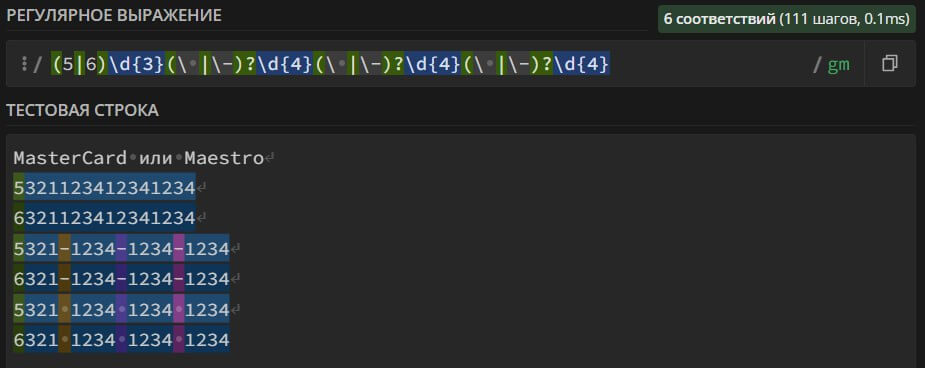
(5|6)\d{3}(\ |\-)?\d{4}(\ |\-)?\d{4}(\ |\-)?\d{4} – search in the text for bank card numbers of the MasterCard or Maestro payment system. The card number can contain spaces, dashes "-" and consist of 16 digits.
# Search for a language mark
Regular expressions for searching for various language signs help to filter users' text by language. It can be used to process user messages if you have multiple chats for an audience from different countries. You can create regular expressions that will search for individual characters and words in a particular language in a message. Or search for messages that are entirely not in the language of your chat.
[A-Za-z] – search for at least one Latin character in the text in the range A-Z (uppercase) or a-z (lowercase).
The regular expression will look for the presence of any one uppercase or lowercase Latin character in the text. It can be absolutely any letter from the alphabet anywhere in the text.
[A-Za-z]+– search in the text for at least one English word consisting of Latin characters in the range A-Z (uppercase) and a-z (lowercase). A word can consist of uppercase and lowercase letters, or only uppercase or lowercase letters.
Such a regular expression will allow the content of 1 Latin character in the text, but react to a word consisting entirely of them. This is a mild regular expression that forgives typos in the text (hllo), but reacts to English words.
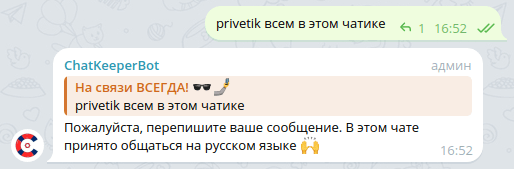
[^A-Za-z] – search for at least one character in the text, except Latin characters in the range A-Z (uppercase) or a-z (lowercase).
Such regular expressions prohibit the use of characters in any language other than English in the text. The text must consist entirely of Latin letters so that the trigger does not work.
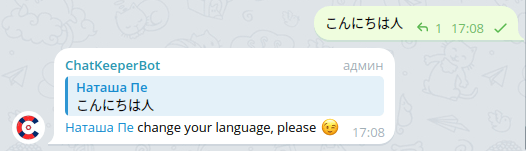
[А-Яа-я] – search for at least one Cyrillic character in the text in the range A-Z (uppercase) or a-z (lowercase).
The regular expression will look for the presence of any one uppercase or lowercase Cyrillic character in the text. It can be absolutely any letter from the alphabet anywhere in the text.
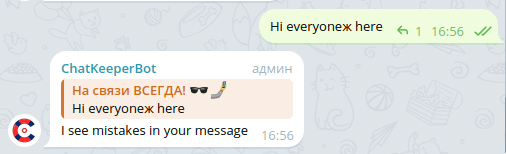
[^А-Яа-я] – search in the text for at least one character other than Cyrillic in the range A-Z (uppercase) or a-z (lowercase).