# Регулярные выражения
Предисловие
Регулярные выражения в нашем случае – мощнейший инструмент для поиска каких-либо строк в сообщениях пользователя. Их, как условия для последующего совершения каких-либо действий, можно использовать в фильтре «Регулярные выражения» и в условиях триггеров.
Согласитесь, не всегда можно явно (например, с помощью условия «Сообщение содержит» в триггере) указать то, на что должен реагировать бот. Без этого инструмента не скажешь, что указанные слова должны стоять друг от друга не дальше, чем на N символов друг от друга, не всегда удобно перечислять все формы требуемого слова.
Кроме того, через регулярные выражения можно сделать почти все условия (относящиеся к тексту сообщений) в триггерах. Исходя лишь из этого можно понять, что этот инструмент сможет открыть перед вами широкие возможности.
Регулярки используются во всех популярных языках программирования, но в каждом из них есть небольшие отличия по синтаксису. Во избежание недоразумений, предупреждаем: ChatKeeperBot использует регулярки языка Java.
Проверить своё регулярное выражение вы можете в личном кабинете, в верхней панели есть кнопка "Помощь" , нажав на «Тестировать регулярное выражение».
Как это всё работает?
Несмотря на то, что это всё сложно, это просто. Прочитав эту статью, вы сможете быстро понять основные принципы работы регулярок, изучая приведённые нами примеры станет ещё более понятно, ну а если у вас останутся вопросы, мы на них ответим. Итак, начнём.
Если в тестере регулярных выражений вписать регулярку (привет), и текст ниже, то мы получим аналог условия «Сообщение содержит»:

Итак, здесь можно проследить суть регулярных выражений – они призваны искать какой-то шаблон в тексте, а в случае @ChatKeeperBot – то слово/выражение в сообщениях пользователей, на которое должен будет сработать триггер.
Можно увидеть, что регулярное выражение написано в скобках. Они служат для выделения какой-то общей части, как в математике. В простых случаях, как в этом, они могут быть опущены. Со временем вы будете ставить их интуитивно. Надеюсь, вы поняли, как использовать тестер регулярок на нашем сайте – нужно вписать регулярное выражение в верхнюю строку, а ниже написать текст, в котором он должен будет найти (или не найти) нужный вам шаблон.
Текст в регулярке является регистрозависимым. То есть, если написать регулярку (ПрИвЕт), соответствовать ему будет только строка «ПрИвЕт», но не «Привет». Для того, чтобы не учитывать регистр, можно ниже, в фильтрах условия поставить галочку "Не учитывать регистр"
Символы, посредством которых и будет происходить вся магия, описанная выше, в этом списке:
. ^ $ * - + ? { } [ ] \ | ( )
Если нужно найти строку, содержащую один из этих символов (например, строку «всё.»), необходимо экранировать этот символ – добавить перед символом обратную косую черту. Регулярка будет выглядеть так: (всё.)
Или я, или эти мерзкие обои в цветочек
Самое первое, с чем я вас познакомлю, это знак «|». Он аналогичен слову «ИЛИ». Здесь всё предельно просто: регулярка (пере|дымо)(ход|кур) будет срабатывать на 4 слова: переход, перекур, дымоход, дымокур.

Наборы
Чтобы указать, что на определённом месте может стоять один из перечисленных символов, используются наборы. Необходимые символы записываются в квадратные скобки. Так, регулярка (пр[еию]вет) сработает на «привет», «превет», «прювет».
Если перед символами в наборе поставить знак «^», то регулярка будет срабатывать всегда, когда на данном месте нет всех перечисленных символов. Регулярка (пр[^ауе]вет) работает на «привет», «прывет», «прьвет», «пр7вет», но только не на «правет», «прувет» и «превет».

Объясните для себя, почему один пример принимается, а другой не подходит.
Также, наборы можно комбинировать друг с другом:

И ещё пара приёмов:
[а-г[ф-я]] объединение символов (от а до г и от ф до я)
[а-я&&[клмн]] пересечение символов (символы к, л, м, н)
[а-я&&[^б-э]] вычитание символов (символы а, ю, я)
Диапазоны
Как бы вы обозначили любую букву русского алфавита? ([абвгдеёжзик.... – совершенно верно, но это очень громоздко. Через тире можно обозначить диапазон знаков: ([а-я]). Так можно сделать благодаря тому, что в Юникоде все буквы расположены последовательно, кроме буквы ё. Таким образом, букву русского алфавита в нижнем регистре можно записать так: ([а-яё]), а без учёта регистра так: ([а-яА-ЯёЁ]). По аналогии, любая цифра: ([0-9]). Регулярному выражению ([о-р]р[з-к][б-г]е[^а-су-я]) может соответствовать строка «привет».
Ещё раз, [fд7] – это f ИЛИ д ИЛИ 7.
[^9qы] – это НЕ 9 И НЕ q НЕ ы
Для некоторых наборов, которые используются достаточно часто, существуют специальные обозначения. Так, для описания любого невидимого символа (пробел, табуляция, перенос строки) используется \s, для цифр - \d, для символов латиницы, цифр и знака подчёркивания - \w.
Если указанные наборы написать с заглавной буквы (\S, \D, \W) то они поменяют свой смысл на противоположный: \S - любой непробельный символ, \D - любой символ, который не является цифрой, \W любой символ кроме латиницы, цифр или подчёркивания соответственно. Если необходимо описать вообще любой символ, для этого используется точка — «.». Такие наборы иногда называют метасимволами.
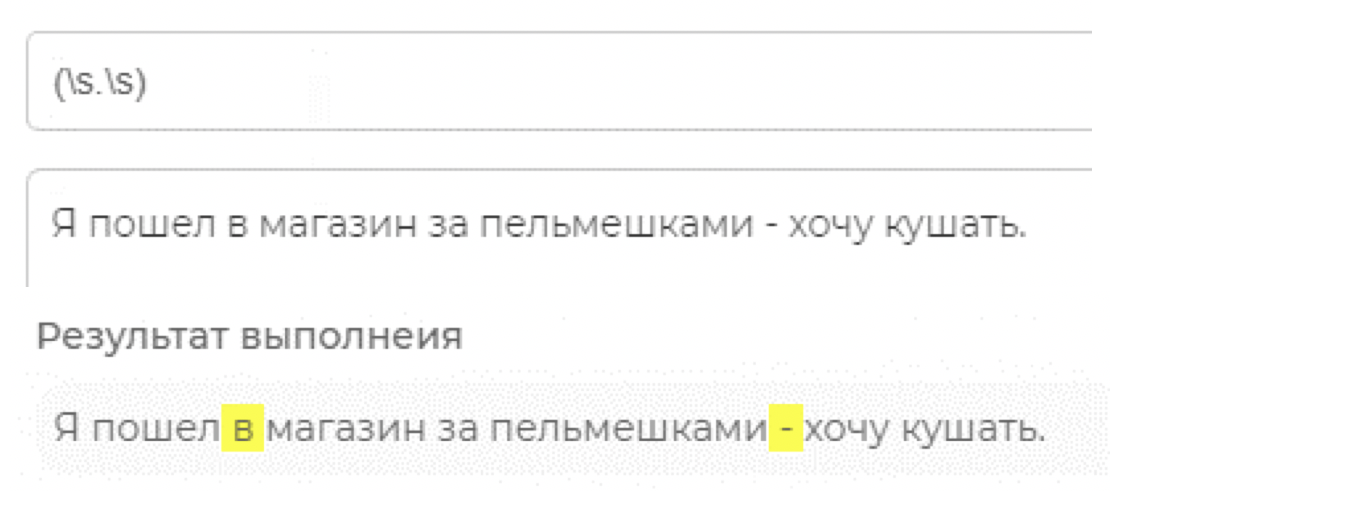
Выше реализован поиск символов, ограниченных двумя «невидимыми» знаками. Если бы в тексте стояло три пробела подряд, они бы тоже были выделены, так как «.» - абсолютно любой символ, в том числе и пробел.
Давайте разберём пару трудных примеров:

Под «нецифру» (\D) попадают также символы переноса строки, пробелы, подчеркивания, поэтому выделены цифры «3» и «2» в первых двух строках, между которыми есть невидимый знак переноса строки. Строка «2q3» не выделена, потому что часть этой строки уже входит в предыдущий шаблон, и поиск вновь продолжился с символов «q3».
Ещё один пример:

Разберёмся подробнее. Справа и слева \d – то есть цифры. Что же находится в середине? Там находится: не невидимый символ и не цифра. Исходя из этого, остальные шаблоны подходить не могут.
Нет ничего невозможного. Границы только у нас в голове.
Граница или не граница слова обозначаются символами \b и \B. Предлагаю пример для рассмотрения:
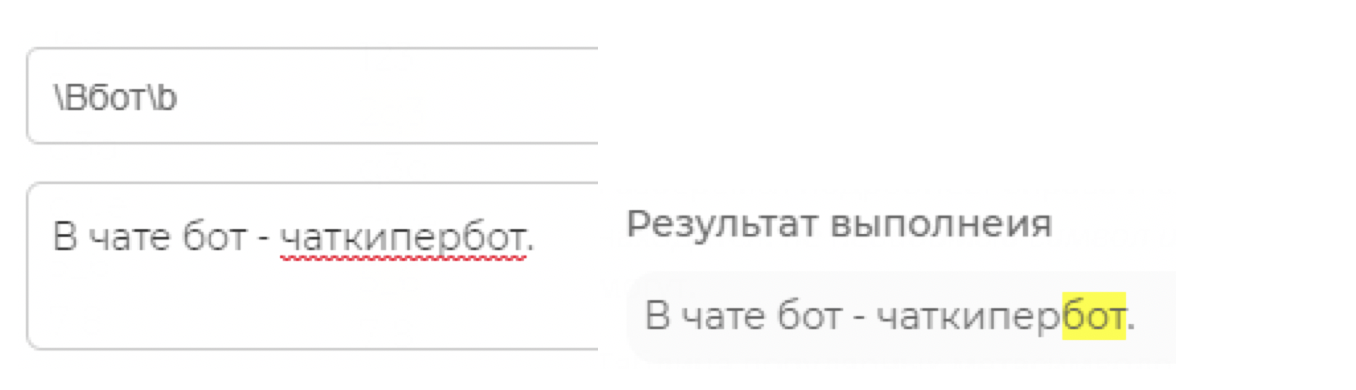
Знак ^ означает начало ввода, $ - конец ввода.

Квантификаторы (указание количества повторений)
Этот инструмент, например, позволит вам найти трудноугадываемое словосочетание или выражение в сообщении пользователя. Пусть у вас группа, связанная с кулинарией, и туда заходит много новичков, спрашивая как сделать блюда, и вы их хотите отправлять с такими вопросами на какой-нибдуь ресурс с этой информацией. Он может спросить «как сделать пиццу», или «как делать эту пиццу», или «как вы делаете такие пиццы», и вместо «эту» и «такие» ещё полсотни вариантов. Поэтому надо сказать, что между словами «делать» и «пицца» толжно стоять, скажем, 20 знаков. Сделать это можно следующим образом: регулярка приве{1,5}т будет соответствовать словам «привет», в которых от 1 до 5 букв «е» включительно: «привет», «привееет» или «привееееет». Кроме того, вторую цифру можно опустить: приве{1,}т – означает один или более раз будет встречаться буква «е» в слове привет; е{3} – определённое количество раз. Кроме того, есть специальные символы для обозначения некоторых квантификаторов, они ниже. Подитожим:
{n} символ повторяется n раз
{n,} символ повторяется n и более раз
{n,m} не менее n раз и не более m раз
? один или отсутствует (аналог {0,1})
- ноль или более раз (аналог {0,})
- один или более раз (аналог {1,})
Итак, вернёмся к примеру с пиццей. Теперь мы можем осуществить желаемое, оставим вместо глагола «сделать» буквы «дела», чтобы захватывались все формы слова (делали, делаем и т. д.), с пиццей проще – можно оставить только «пицц»:
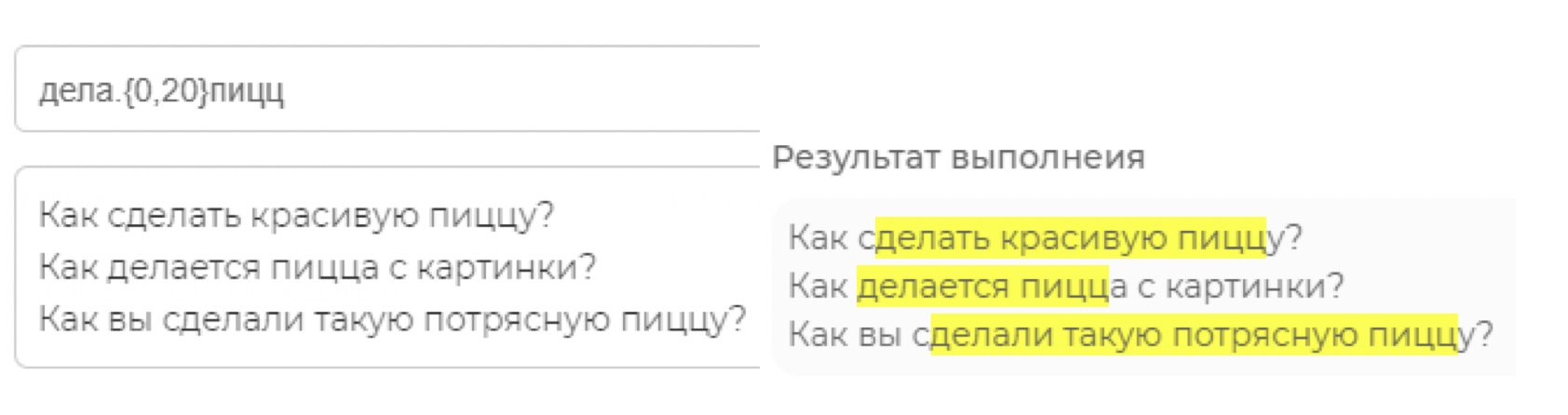
Но есть маленькая ошибка. Может быть сообщение: «Такие вот дела, пицца оказалась невкусной», на которое также сработает регулярка. Что делать? Всё очень просто, указать возможные буквы после «дела» для глагола, вот они: [летю] (делали, делаю, делаете, делать)

Можно также добавить знак вопроса вконце, исключив случаи утверждений, например: «Я знаю, как сделать такую пиццу.». Для этого регулярку можно сделать такой: дела[летю].{0,20}пицц.? В конце регулярки мы говорим, что после «пицц» и перед «?» должно стоять ноль или более символов.
Если поступать совсем правильно, то можно попутно избежать того, что эти слова будут находиться в разных предожениях. Предложения могут заканчиваться точкой, восклицательным или вопросительным знаком. И тогда мы точки в регулярке (любой символ) заменим на «не знак окончания предложения», обязательно экранируя «.» и «?»: [^.?!], для второй точки опустим знак вопроса, поскольку он нам и нужен. Получится: дела[летю][^.?!]{0,20}пицц[^.!]?
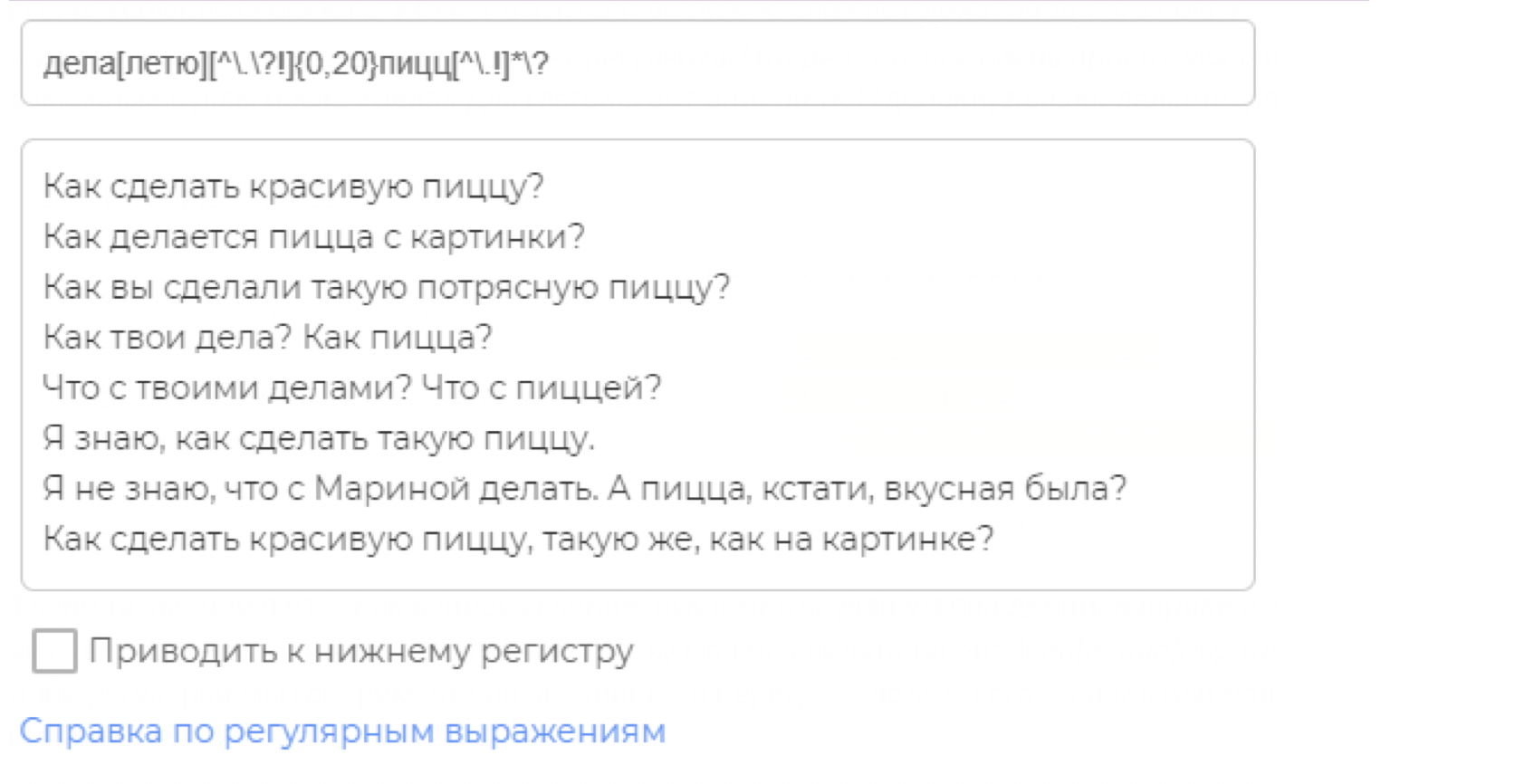

Таблица популярных метасимволов (здесь собраны не все, потому что во-первых, вероятность использования некоторых равна нулю, а во-вторых, некоторые в боте просто невозможно использовать).
^ начало строки (начало сообщения)
$ конец строки (конец сообщения)
\b граница слова
\B не граница слова
\d цифровой символ
\D нецифровой символ
\s символ пробела
\S непробельный символ
\w буквенно-цифровой символ или знак подчёркивания
\W любой символ, кроме буквенного, цифрового или знака подчёркивания
. любой символ
\t символ табуляции
\n символ новой строки
{n} символ повторяется n раз
{n,} символ повторяется n и более раз
{n,m} не менее n раз и не более m раз
? один или отсутствует (аналог {0,1})
ноль или более раз (аналог {0,})<br/>
один или более раз (аналог {1,})<br/>
| логическое «ИЛИ»
[а-я&&[клмн]] пересечение символов (символы к, л, м, н)
# Шаблоны регулярных выражений
Вы можете использовать готовые шаблоны регулярных выражений для триггеров и фильтров спама.
# Поиск номера телефона
Регулярные выражения по поиску разных номеров телефонов могут быть полезны для группы в нескольких случаях:
- уберечь группу от спама и мошенничества
- обозначить обязательные условия для публикации. Например: объявлении о вакансии с указанием телефона для связи.
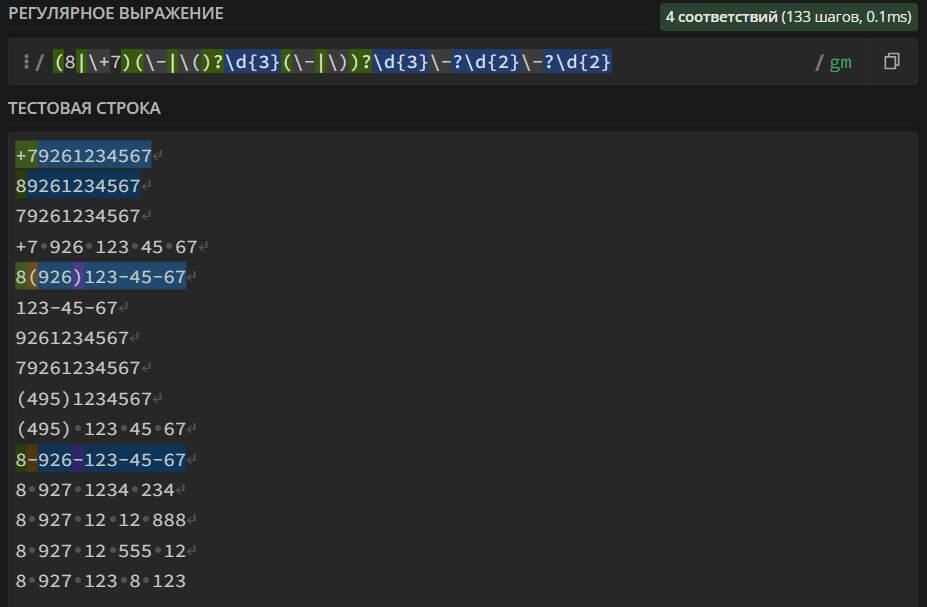
((8|\+7)[\- ]?)?(\(?\d{3}\)?[\- ]?)?[\d- ]{7,10}
– поиск в тексте городского или мобильного номера телефона, который может содержать скобки « ()», черточки «-», пробелы, код города «8» или «+7» и состоять от 7 до 10 цифр, без учета кода города.
Данное регулярное выражение является универсальным и подходит для поиска всех популярных форматов написания мобильных и городских номеров. Оно одинаково подходит для борьбы со спамом и для проверки объявлений группы с обязательным указанием контактов.
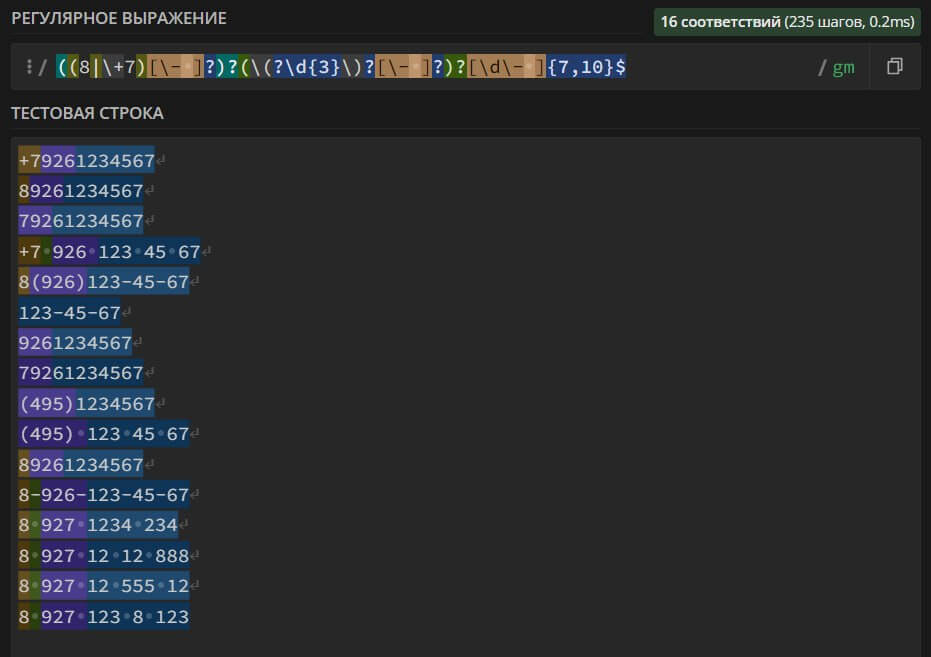
(8|\+7)\d{10} – поиск в тексте номера мобильного телефона, который может содержать код города «8» или «+7». Номер может состоять только из 10 цифр, без учета кода города.
Это регулярное выражение является строгим. Оно подходит для поиска всего 2х форматов мобильного номера телефона. Оно не подходит для борьбы со спамом, но его можно можно использовать, если у вас строгие требования к публикациям в группе.
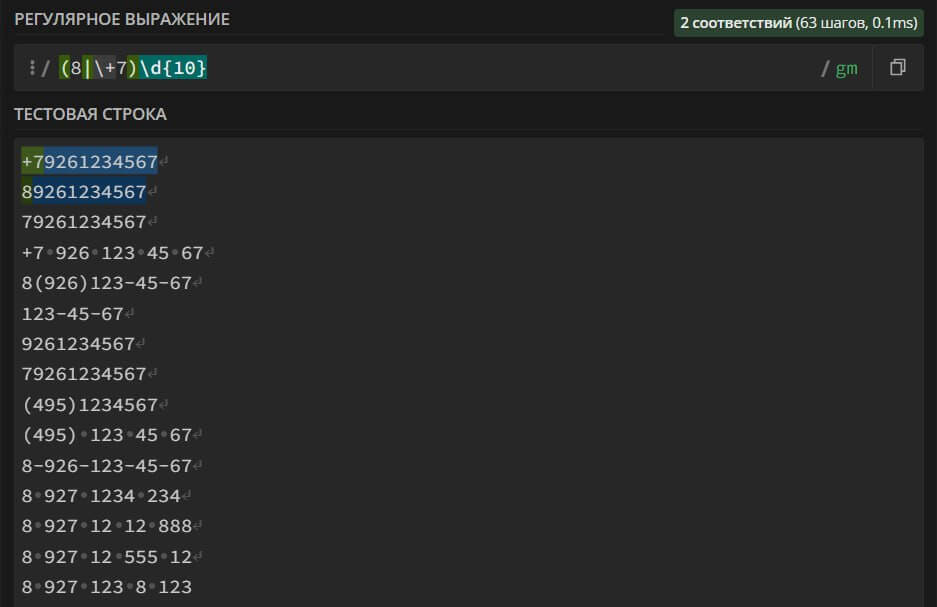
(8|\+7)(\-|()?\d{3}(\-|\))?\d{3}\-?\d{2}\-?\d{2} – поиск в тексте номера мобильного телефона, который может содержать скобки « ()», черточки «-», код города «8» или «+7». Номер может состоять только из 10 цифр, без учета кода города.
# Поиск номера банковских карт
Регулярные выражения по поиску различных номеров банковских карт относятся к тем же категориям: предотвращение спама и проверки объявлений группы.
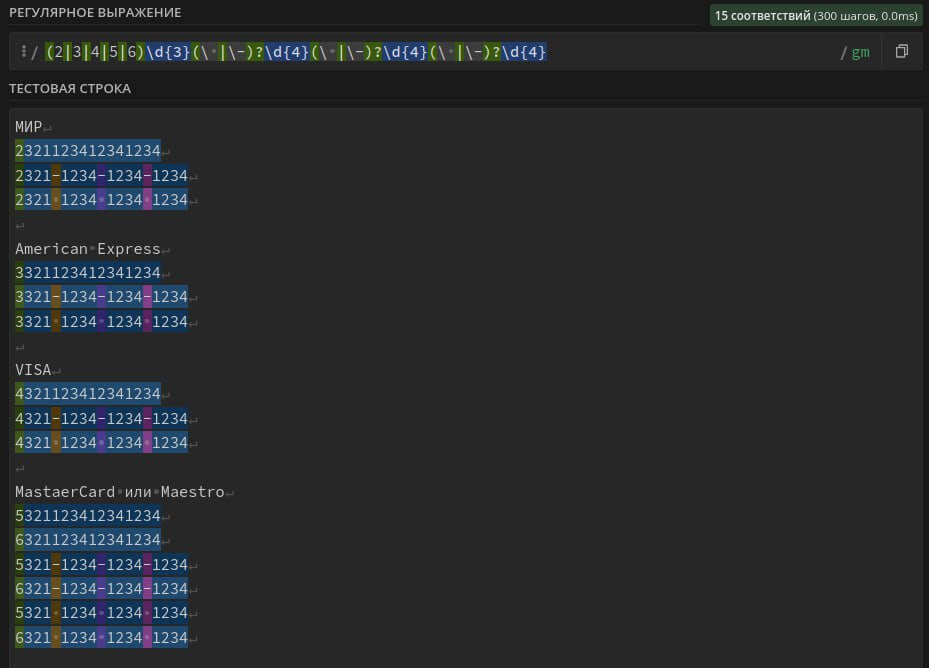
(2|3|4|5|6)\d{3}(\ |-)?\d{4}(\ |-)?\d{4}(\ |-)?\d{4} – поиск в тексте номеров банковских карт с типами платежных систем Visa, MasterCard, Maestro, American Express, МИР. Номер карты может содержать пробелы, черточки «-» и состоять из 16 цифр.
Регулярное выражение является универсальным, подходит для поиска всех популярных форматов написания номеров банковских карт и учитывает большинство платежных систем.
(2|3|4|5|6)\d{15} – поиск в тексте номеров банковских карт с типами платежных систем Visa, MasterCard, Maestro, American Express, МИР. Номер карты может состоять из 16 цифр.
Строгое регулярное выражение и с ограниченным типом проверки написания номера. Пробелы и черточки не учитываются. Реагирует только на слитное написание номера карты.
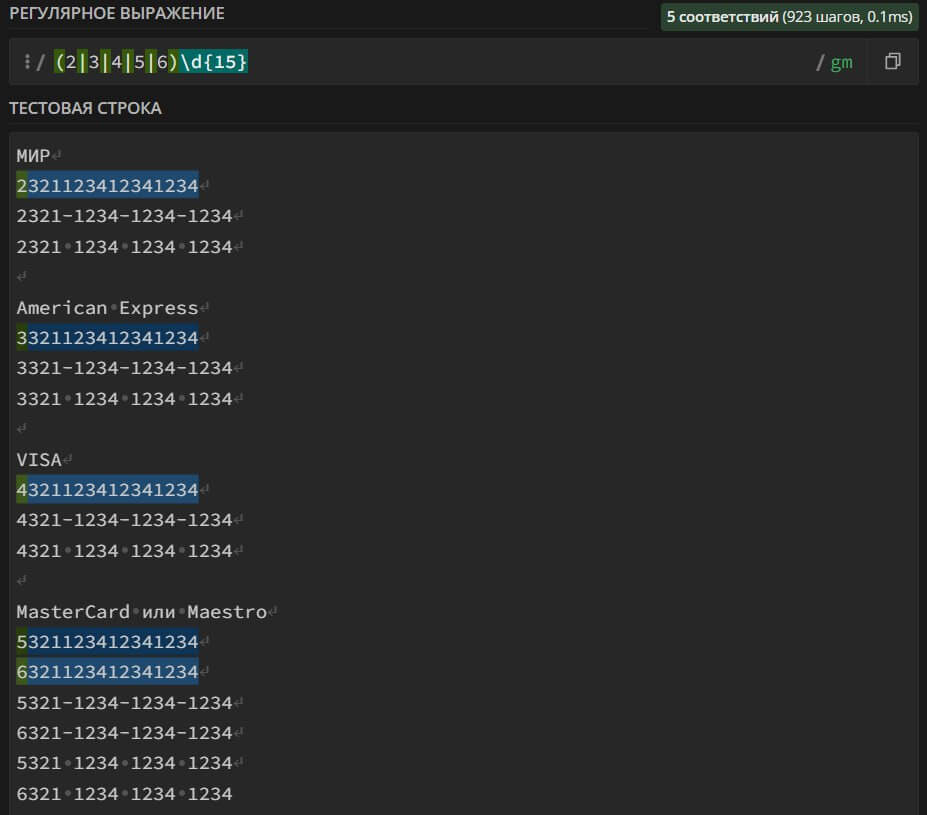
2\d{3}(\ |\-)?\d{4}(\ |\-)?\d{4}(\ |\-)?\d{4} – поиск в тексте номеров банковских карт платежной системы МИР. Номер карты может содержать пробелы, черточки «-» и состоять из 16 цифр.
Регулярное выражение для поиска карт всего 1 типа платежной системы. Можно использовать для русскоязычных чатов.
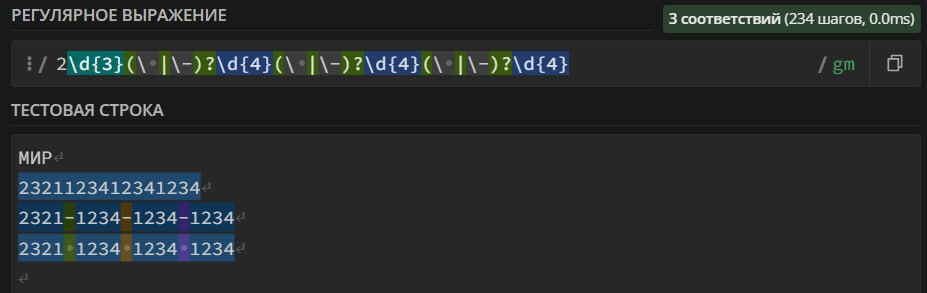
3\d{3}(\ |\-)?\d{4}(\ |\-)?\d{4}(\ |\-)?\d{4} – поиск в тексте номеров банковских карт платежной системы American Express . Номер карты может содержать пробелы, черточки «-» и состоять из 16 цифр.
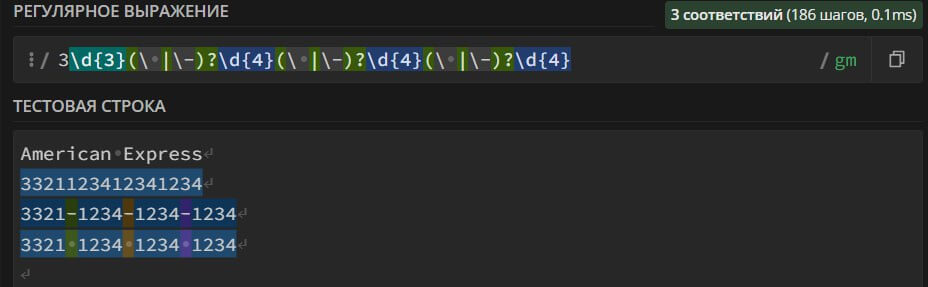
4\d{3}(\ |\-)?\d{4}(\ |\-)?\d{4}(\ |\-)?\d{4} – поиск в тексте номеров банковских карт платежной системы VISA. Номер карты может содержать пробелы, черточки «-» и состоять из 16 цифр.
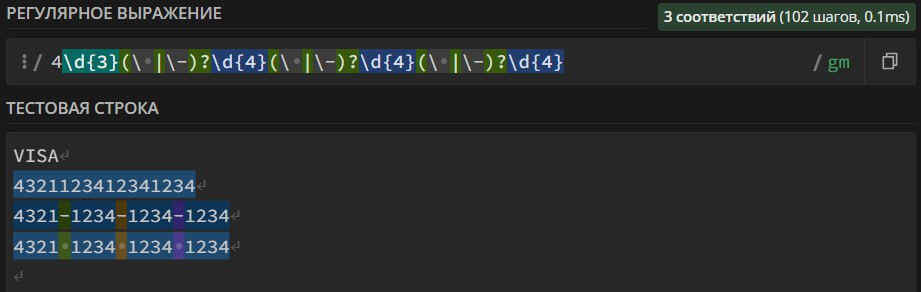
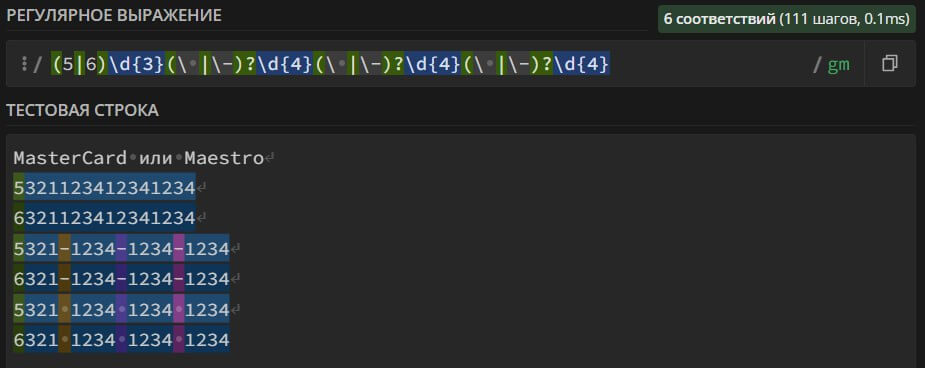
(5|6)\d{3}(\ |\-)?\d{4}(\ |\-)?\d{4}(\ |\-)?\d{4} – поиск в тексте номеров банковских карт платежной системы MasterCard или Maestro. Номер карты может содержать пробелы, черточки «-» и состоять из 16 цифр.
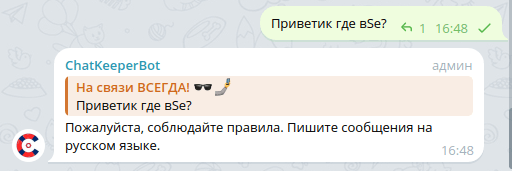
# Поиск языкового знака
Регулярные выражения по поиску различных языковых знаков помогают фильтровать текст пользователей по языкам. Его можно использовать для обработки сообщений пользователей, если у вас несколько чатов для аудитории из разных стран. Вы можете создавать регулярные выражения, которые будут искать в сообщении отдельные символы и слова на определенном языке. Или искать сообщения, целиком состоящие не на языке вашего чата.
[A-Za-z] – поиск в тексте хотя бы одного любого латинского символа в диапазоне A-Z (прописные) или a-z (сточные).
Регулярное выражение будет искать в тексте наличие одного любого прописного или строчного латинского символа. Это может быть абсолютно любая буква из алфавита в любом месте текста.
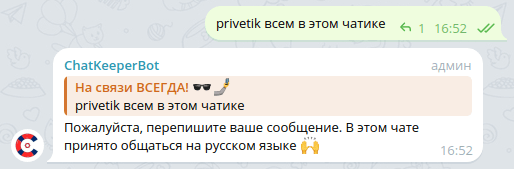
[A-Za-z]+ – поиск в тексте хотя бы одного любого английского слова, состоящего из латинских символов в диапазоне A-Z (прописные) и a-z (сточные). Слово может состоять из прописных и строчных букв или только из прописных или строчных букв.
Такие регулярные выражением будет допускать содержание в тексте 1 латинского символа, но реагировать на слово, полностью состоящее из них. Это мягкое регулярное выражение, которое прощает опечатки в тексте ( прbвет), но реагирует на английские слова.
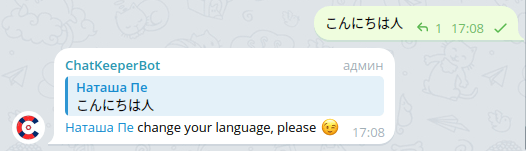
[^A-Za-z] – поиск в тексте хотя бы одного любого символа, кроме латинских в диапазоне A-Z (прописные) или a-z (сточные).
Такие регулярные выражением запрещает использование в тексте символы любых языков, кроме английского. Текст должен полностью состоять из латинских букв, чтобы триггер не сработал.
[А-Яа-я] – поиск в тексте хотя бы одного любого символа на кириллице в диапазоне А-Я (прописные) или а-я (сточные).
Регулярное выражение будет искать в тексте наличие одного любого прописного или строчного символа кириллицы. Это может быть абсолютно любая буква из алфавита в любом месте текста.
[^А-Яа-я] – поиск в тексте хотя бы одного любого символа, кроме кириллицы в диапазоне А-Я (прописные) или а-я (сточные).